This note is an update on the note that I wrote back in 2016-08-22.
In 2013, I started a system for augmenting my paper journal with a
computer-searchable index. In this note, I'll describe how my system works,
what tools I use to interact with with it, some of the unexpected emergent
complexity of the indexing system, and what I'd like to do with it next.
Full disclosure: The computer index is of questionable utility. I do not
refer to things in the index very often in my day-to-day life. The most common
use of the index is looking up all the references to someone who has recently
died. I'm a member of a church with an aging congregation, and so it happens
two or three times a year that I need to look someone up. Usually, the most
active engagement with the index is during the winter holidays when I re-read
the year's journals. That holiday tradition, in itself, justifies keeping an
index.
I started to keep a running index of my journal in graduate school. At the
time, I was interested in board games and admired the work of Sid Sackson.
In a magazine article about Sid, I found out that he kept a game development
journal where he logged all the game-related activity in his life. Anything
that seemed important was written in upper-case letters. At the end
of each year, he manually compiled an index to that year's volume of the journal
and would add a dot beside uppercase in the journal that made it to the
index. Sid Sackson's diary
has been scanned and put online by the Museum of Play. It is definitely worth checking out!
The Indexer
My method of indexing is similar to Sid Sackson's method, except that I use a
computer to handle the compilation. The indexer is about fifty
lines of Perl code. It takes a directory full of plaintext files, one per
volume, and returns an index of the whole journal. For each volume, I make a
plaintext file (called a date file) which lists the subjects mentioned on each
date using the following bare-bones format:
2017-09-21:
[07:45]
@HartHouse
Shoulder problem
Fisherman's Friend
2017-09-23:
@TaddleCreekPark
[16:15]
Dagmar Rajagopal
Dagmar Rajagopal's memorial Meeting
The indexer then converts this information in to an index which lists where
each subject appears in the journal. For example, the entry for @HartHouse reads:
@HartHouse - 2017-09-21, 2017-09-27, 2017-10-02, 2017-10-04, 2017-10-13,
2017-10-18, 2017-10-30, 2018-02-09, 2018-04-04, 2018-04-06, 2018-09-04
The indexer also prints some statistics about the index:
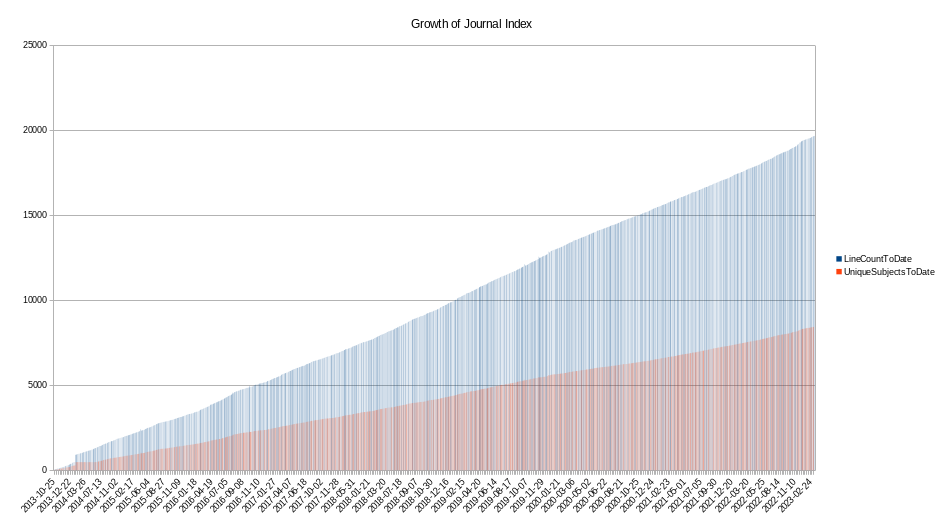
Indexing all volumes.
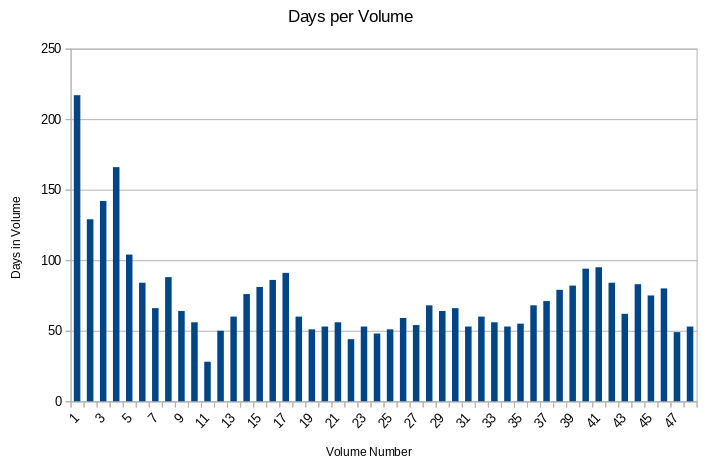
number of volumes
40
days with entries
1602
number of references
17021 ./date.all
distinct subjects referenced
7237 ./subject.all
Emergent Structure
The plaintext format of the index has almost no structure. It does not contain
any kind of markup to denote what each line means. This is a weakness and a
strength of the system. The indexer doesn't know anything about what each line
means, but I am free to create any kind of structures that I want with
plaintext.
The very first date file begins:
2013-10-24:
FRM
FillRad
FillVol
Algebraic Geometry
2013-10-25:
Quaker
Bill Taber
Flat Surfaces
PGG Seminar
Marcin Kotowski
Matt Sourisseau
Design a computer from scratch
Sam Chapin
Tyler Holden
These entries contain a mix of things: some math topics, a religion, an author,
some more math topics, some friends, a project name, and some more friends. At
this early stage, the index did not have any clear guidelines for formatting
subjects, or what to include and exclude.
2015-11-06:
MAT 246
Tyler Holden
UoT
Sam Chapin
Linux
Canada
Mathematics in Canada
[22:00]
About two years later, on 2015-11-06, the first entry with a timestamp appears.
The timestamps are written in the date files as [HH:MM]. The left bracket sets
them apart in the index, and they all sort to a contiguous block of entries.
2016-06-04:
Elizabeth Block
Sylvia Grady
Mark Ebden
Camp NeeKauNis
@NeeKauNis
On 2016-06-04, another structure emerged. Entries after this point typically
include both an [HH:MM] timestamp and a @Location tag. Each entry in the
(physical) journal typically begins with a line like:
@HeronPark 2021 XII 20 II [21:35]
This is very far from the One True Date Format (ISO 8601). Allow me to explain.
This date format is a mash-up of idiosyncracies.
I learned about representing months using Roman numerals from Marcin and Michał Kotowski when they participated in the Probability, Geometry, and Groups Seminar. According to Wikipedia, this is usage of roman numerals for months is still common in Poland.
Prior to learning about this convention, I wrote dates as 2021/12/20 which seems visually busy and homogenous.
The Roman numerals break things up a bit. Also, it seems fitting to use Roman numerals for months.
The second Roman numeral in the date stamp is the day of the week.
In the Quaker calendar, Sunday is the first day of the week.
Sometimes, I have heard contemporary Quakers using ordinals for day names,
but it is quite rare to hear anything other than "First Day".
DIAGRAM - 2015-04-13, 2015-05-29, ..., 2020-12-28, 2021-02-02
There are some indexing conventions that I adopted early on and that I don't
like very much. The worst is probably the convention for writing DIAGRAM when
a diagram appears in an entry. There are ~150 entries with diagrams, and I have
no idea what any of the diagrams represent. Someday, I might go back and track
them all down, but it will be a lot of work. (At least I know where to look!)
The upper case convention for tagging information is not great. The intent was
to have a mechanism for indexing structural things such as DIAGRAM, LIST,
CALCULATION. Each of the these labels should have some more description added
to it. The issue is that they don't sort to any particular place in the final
index and so they are hard to track down. One needs to know, in advance, all
the possible upper case subjects to find anything.
Brokhos - 2018-07-26
Brokhos (SF) - 2019-06-06
Brokhos (sf) - 2018-06-24, 2018-02-03, 2018-03-04, 2018-07-31
There are also things where the correct convention is slowly emerging. The
three subjects above are supposed to refer to the string figure called
Brokhos. I'm not sure if appending
things like (sf) or (SF) is helpful. It is easy enough to look for all the
string figures in the index by looking for (sf) or (SF). Perhaps a more useful
convention would be "String Figure: Brokhos". Whenever I have looked up a
string figure from the index, I just used its name and so have not needed the
tag in brackets.
This project continues to grow and evolve. Some conventions have stabilized and
are very helpful. Every year, new conventions crop-up. I have not (yet) gone
back and revised the index for consistency, so there is a hodge-podge of
competing conventions. This is not project for publication, but is an on-going
exploration of writing and journaling.
Managing these files with vim
The workflow surrounding the index is vim based.
I run vim ~/Work/Journal/date/date.* to open up all the date files in different buffers. This makes all the material in the index available when I want to start indexing a new volume.
The format for date files essentially uses one line per subject. Vim supports whole line completion using CTRL-X CTRL-L which pull possible line completions from all buffers. (For details, see: :help compl-whole-line.) This makes completing complicated names like "Ivan Khatchatourian" straightforward.
As I'm writing a date file, I keep the current date in the register "d (for date). While
putting together the date file for the volume containing December 2021, I'll
keep 2021-12-01: in the "d buffer.
So, the vim workflow looks like:
- Paste in a date.
- Modify it appropriately.
- Use whole line completion to add new subjects
- Repeat.
Pen and Paper
This write-up wouldn't be complete without saying a little bit about the
physical side of the journals too. I've used hard bound 4x6" sketchbooks since
the index started. They are absolutely indestructible, neither too big nor too
small, and quite cheap. Another notable feature is that you can find them at
any art supply shop.
I write with a
Kaweco Sport Brass fountain pen using J. Herbin Lierre Sauvage ink. The brass pen has a nice weight to it. It's a pen that's hard to misplace and no on has walked away with it. I use it for all my writing because ball point pens severely aggravate my tennis elbow.
Originally, I got all my books from Toose Art Supplies because they were across the street from the
math department. Now, I tend to get things from Midoco:
Closing Note
2021-06-11:
@HeronPark
[15:30]
"Your diary is an on-going and growing project. You are free to alter, change and experiment with it as you wish. Whoever receives it will make of it whatever they make of it. Strike out and explore. Or, dream the same old dreams. This is your place; enjoy it!"
Contact Me About This
There do not seem to be many people doing this sort of thing. The only examples
that I know are Soren Bjornstad and Dave Gauer. If you're using computers to
index your personal journal, or are interested in doing so, I would love to get
in contact with you.